![]()
 大数据文摘
大数据文摘当人工智能看起来十分正确时,我们又将面临什么问题。
大数据文摘出品
来源:New Yorker
编译:张卓骏、武帅、易琬玉
莫达非尼(modafinil)是一种常用的觉醒促进剂,用于治疗睡眠紊乱、嗜睡症等。如果你仔细阅读它的说明书,你会发现内容十分硬核无聊,也就是市面上常见的Provigil,和很多药物一样,都被包装在一个小纸盒里。
纸盒里大部分内容都是用于提示说明,包括药物使用说明及注意事项、药物分子结构示意图。但是,在“作用机制”部分,却有这么一句吓死人的话——其中关于“药物作用机制”的一小部分内容,尤其是一句特定的描述则可能会让人无语到想入睡——“有关莫达非尼如何使人保持清醒的作用机制尚不明了!”。
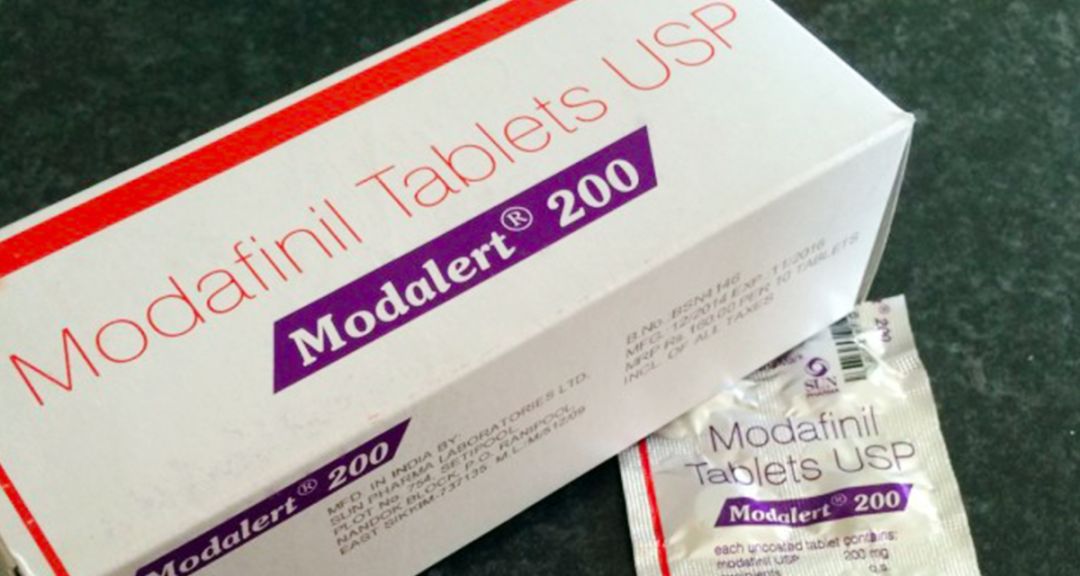
像莫达非尼一样神秘莫测的药物不在少数。很多药物尽管获得了监管部门的批准,并且被广泛使用,但实际上也没人知道它们到底是如何起作用的。
这种神秘性源自于通过反复试验进行药物开发的过程。新药物每年都会在人工培养的细胞或动物身上试验,而其中最好且最安全的药物才会进行人体试验。在某些情况下,药物的成功会促进新的研究从而解释药物的作用机制。比如,1897年阿司匹林问世,但直到1995年才有人真正解释了它是如何起作用的。
医学领域里,这种现象比比皆是。深度脑部刺激需要将电极插入患有特定行动障碍(如帕金森病)的患者脑部。这种方法已被广泛使用二十多年,还有些人认为应该扩大它的使用范围,如提高一般认知能力等。然而,没有人能说清它的作用机制。
这种先找答案再解释的方法,称为“智力债务”。
在某些情况下,我们会马上还清这笔智力债务。但是,其他情况下,我们可能几十年都难以证实所用的方法理论。
人工智能新技术提高了我们的“智力债务”
在过去,智力债务一直局限于一些需要进行反复试验的领域,如医学。但现在这种情况发生了变化。
随着人工智能新技术,特别是机器学习的出现,我们的“智力信用额度”被提高了。机器学习系统在数据海洋中识别模式,并借助这些模式来解决一些模糊开放的问题。例如,提供一个有关猫和其他非猫科动物的标记图片数据集,机器学习系统就学会了如何识别猫。同样地,让系统访问医疗记录,它就可以尝试预测一个新入院病人的死亡可能性。
然而,大多数的机器学习系统并没有发现因果机制(causal mechanisms)。基于统计相关性引擎的机器学习系统无法解释为什么它们认为某些患者更有可能死亡,因为它们并不考虑数据的含义,而只是提供结果。当我们将这些系统融入日常生活时,我们将共同承担越来越多的智力债务。
制药领域的发展表明,在某些情况下,智力债务是不可或缺的。那些我们并不理解的干预措施已经挽救了数百万人的生命。很少有人会因为不清楚其作用机制而拒绝服用拯救生命的药物,如阿司匹林。
但是,智力债务的增加也会带来不好的结果。随着具有未知作用机制的药物激增,发现不良反应所需的测试数量呈指数级增长。
如果清楚药物的作用机制,就可以预测其不良反应。在实践中,药品间的相互作用往往是在新药上市后才发现的,这就形成了一个循环。在这个循环中,药物先被上市,然后被遗弃,期间还伴随着集体诉讼。
通常,伴随着新药产生的智力债务有一定的合理性。但是智力债务并不是孤立存在的。在不同领域发现和部署的没有理论基础的答案,会以不可预测的方式使彼此交错复杂化。

通过机器学习产生的智力债务风险已经超出了过去反复试验纠正所带来的风险。因为大多数机器学习模型无法提供做出判断的理由,所以如果它们没有对所提供的答案进行独立判断,那么就不知道它们会在何时失误。训练良好的系统很少出现失误,但如果一些人知道该向系统提供什么数据从而故意制造失误时,那情况就很糟糕了。
以图像识别为例。十年前,计算机还无法轻易地识别出图像中的物体。而今天,图像搜索引擎,像我们日常互动的许多系统一样,都基于极其强大的机器学习模型。
谷歌的图像搜索依赖于名为Inception的神经网络。2017年,一个由麻省理工学院本科生和研究生组成的研究小组LabSix就通过改变一张猫的图像的像素(尽管在人看来它还是一张猫的图像),让Inception有99.99%的把握认为它是一张鳄梨酱的图像。
系统存在未知的漏洞,给了攻击者巨大机会
Inception系统显然无法解释究竟是哪些特征使其能够判断一只猫是否真的是猫,因而当提供特制或损坏的数据给系统时,也很难预测系统是否会出现失误。这些系统在准确性上存在的未知漏洞,无疑给了攻击者机会。
伴随着机器学习系统所生成的知识的使用,这些差距也就随之产生了。一些医疗AI经过训练后已经能分辨出皮肤肿瘤是良性还是恶性。
然而,就像哈佛医学院和麻省理工学院的研究人员通过改变图片的某些像素骗过系统,让其做出错误的判断,攻击者也可能会利用这些漏洞实施保险欺诈。

在人工智能系统预测能力的诱惑下,我们可能会放弃自身的判断。但是系统存在着被劫持的可能,而我们没有什么简单的方法来验证其答案的正确性。
既然如此,我们能否能为智力债务创建一个资产负债表,从而跟踪那些无理论知识的用途呢?
如果一个AI生成了一个新的披萨配方,那么你无需多言,尽管享用便是了。然而,当我们要用AI进行医疗健康方面的预测推荐时,我们就希望得到充分的信息。
如何建立智力债务的资产负债表
建立并维护整个社会的智力债务的资产负债表可能需要我们改进对商业机密和其他知识产权的处理方式。在城市中,建筑法规要求业主公开披露他们的装修计划。同样地,我们也可以要求图书馆或者大学接受托管,并公开那些公共使用的隐藏数据集和相关算法。这样研究人员就可以探索我们将要依赖的这些AI的模型及基础数据,并通关建立相关理论,在我们智力债务的漏洞和脆弱性“到期”之前支付。

机器学习模型越来越普遍,几乎每个人都可以创建一个。虽然这使得会计变得十分困难。但统计我们的智力债务却是至关重要的。
机器学习系统单独来看会持续产生有用的结果,但是这些系统并不是孤立存在的。这些AI收集并提取整个世界的数据,同时也产生着自身的数据,而其中很大一部分会被其他机器学习系统所使用。就像具有未知作用机制的药物有时会相互作用一样,那些背负智力债务的算法也是如此。
别小看了这些债务叠加产生的影响,因为即使是简单的互动也会导致麻烦。
2011年,一位名叫Michael Eisen通过他的一名学生发现,在亚马逊上售卖的所有普通旧书中最便宜的一本The Making of a Fly: The Genetics of Animal Design副本售价为170万美元,外加3.99美元的运费。第二便宜的副本售价为210万美元。
两个卖家都有上千条好评,当Eisen连续几天访问该书的亚马逊网页后,他发现价格以一种规律持续上涨。A卖家的价格总是B卖家价格的99.83%,而B卖家的价格总是A卖家价格的127.059%。Eisen据此推测A卖家确实有一本副本,因此总是比第二便宜的卖家的价格低那么一点;而B卖家却没有副本,所以价格才会定得更高。如果有人在B卖家订购了这本书,那么B卖家就可以从A卖家那里买过来然后转手卖出。
每个卖家策略的设定都很理性。但正是他们算法的相互作用产生了不合理的结果。数以千计的机器学习模型在不受监管的情况下进行互动所产生的结果更是难以预测。早已部署了尖端机器学习系统的金融市场是此类问题的温床。
去年秋天,摩根大通(J. P. Morgan)分析师Marko Kolanovic认为金融市场的崩溃很容易再次发生,因为现在的交易大多基于自动化系统。智力债务在这些系统的相互作用下不断累积,尽管有时它们并不是正式关联的。如果没有类似于资产负债表这样的东西,我们就无法预测或者回溯这些智力债务是否值得承担。
智力债务的增加也可能改变我们对基础科学和应用技术的思考方式。与那些由政府支持,由学术研究机构运营的大型资本项目(如粒子加速器等)不同,机器学习工具很容易被私营企业或学术界所使用。
实际上,与计算机科学或者统计相关部门相比,Google和Facebook更容易获得那些能够产生有用的预测结果的数据集。商人们很喜欢这些虽然无法解释但足够有用的知识,但智力债务也随之增加了。它由公司所持有,使得那些致力于减少智力债务的学术研究人员难以接触得到。
我们很容易地想到,因为机器学习知识的可用性,那些真正试图理解机器学习背后理论基础的研究者很难再获得资金支持。去年12月,一位蛋白质折叠的研究者Mohammed AlQuraishi撰文探讨了其所在领域的最新进展:比研究人员更准确地预测出蛋白质折叠的机器学习模型的建立。同时,AlQuraishi为研究结果失去理论支持而感到惋惜。
“与这篇论文相比,概念性论文或者提出新理论假设的论文的声望要低得多”,他在接受采访时说到。在机器学习使得发现速度加快的时代面前,那些理论家们显得那么无关紧要,甚至是多余的存在。与创建机器学习模型方面的专业知识相比,对特定领域的知识的重视程度自然也会降低。

金融债务将控制权从借方转移到了贷方,从未来转移到了过去。而不断增加的智力债务也可能转移控制权。一个充斥着不经理解的知识的世界会变成一个没有明显因果联系的世界,而我们只能依赖于我们的数据管家来告诉我们该做什么,什么时候做。例如,一个大学的招生委员会可能会将辛苦和不确定的人员筛选交给机器学习模型。这种方式可能会优化新生群体,不仅是为了学业上的成功,还可以带来和谐的人际关系以及校友的慷慨捐赠。再者,我们理解这个世界的唯一方法可能就是采用我们的AI系统,通过神经网络来微调我们的社交媒体资料,这样我们就能够完全“融入”社会。
也许所有的这些技术都是可行的,但反过来,也会带来相应的问题。时下对人工智能的批评大多集中在它可能出错的方式上:它会产生或复制偏见;它会出错;它可能会被用在不当的地方……
然而,我们也应该担心,当人工智能看起来十分正确时,我们又将面临什么问题。



