![]()

 大数据文摘
大数据文摘全球16万在读高中生亟需一个成绩申请大学

大数据文摘出品
编译:lin
由于疫情的原因,全球受认可度最高的基础教育组织“国际文凭(IB)在今年5月被迫取消了期末统考。
但是,全球16万在读高中生亟需一个成绩申请大学。为了给这些毕业生分配一个可以接受的“高考”成绩,IB做出了一个前所未有的尝试:利用一个统计模型,给各位考试预估成绩。
考生最终得分由IB联合一个技术公司一起,根据学生课程作业、老师预测成绩和其他历史数据,通过模型分析给出,并在7月5日准时公布。
听起来这一评估标准似乎公平可信,毕竟三个模型的参考变量都是基于学生最需要被评估的能力。
但是,事实真的是这样吗?
一位来自纽约贝莱德的数据科学家/定量研究 、伯克利机器学习研究者Ishan对此项决定做出了严厉批评:IB的模式存在着明显的方法论问题,这种模式不可避免地会因为性别、种族和社会经济地位等的差异而歧视某些学生群体。
“这将对弱势学生造成不公平以及严重的影响。一个模型可以选择系统地给女学生在STEM科目上分配较低的分数,并且/或者错误地让黑人学生比亚洲学生更容易不及格。“
你可能会问,这个模型考虑的三个因素跟“族裔”“性别”根本没关系呀,没有相关训练数据和特征,模型怎么可能有歧视?
在一篇长文中,Ishan用数据科学知识和纽约高中的真实数据,详细解释了为什么IB的决定是可怕的,以及在没有性别、种族和社会经济数据输入的情况下,一个模型是如何学会“歧视”的。
IB是什么?
先来看看国际文凭(IB)到底是什么?
IB是一个全球性基础教育机构,为来自世界各地的学生颁发高中文凭。2020年的毕业班有来自144个国家的16.6万名考生,目前受到美国、加拿大、英国、澳洲、纽西兰、欧洲地区,主要大学承认。IB文凭可作为报读高等院校的资历,成绩较佳的学生,都能凭IB文凭考入包括英国的剑桥、牛津大学、以及美国的藤校。
IB的高中生在毕业时有一系列强制性的“离校考试”,你可以把它理解成一个全球通用的”高考“。这一系列考试的分数,对学生来说非常重要:是毕业、申请大学的重要指标,也是欧洲和亚洲大学招生过程中最重要的衡量标准(约占90%的权重)。一个学生的期末成绩会极大地改变他们未来,跟咱们的高考重要程度相比,一点不差。
这场疫情给国际文凭组织的计划和运作带来了相当大的混乱。由于课程中断,国际文凭组织被迫取消了现有学生的期末考试。相反,它选择以一种真正前所未有的方式给学生们打分。这里我们引用IB在5月份通告的原话:
IB成员正在与一个专门从事数据分析、标准、评估和认证的教育机构合作,共同开发了一种方法,使用历史数据和当下的数据,来得出每个学生的科目分数。IB一直在与世界各地的教育部门、教育监管机构和其他类似机构进行对话,以确保他们也对我们的方法充满信心,并确保学生获得恰当的认可。 这些评估安排代表了我们对所有学生所能采取的最公平的方法。
根据IB的规定,每个学生的最终成绩将由一个包含两个或两个以上指标的统计模型来分配:
课程作业成绩:学生在课程中断前提交的项目和作业成绩。
预测成绩:教师认为如果考试按计划进行,每个学生可能获得的成绩。这是老师对学生备考能力的评价。
其他杂项数据:IB说模型将使用其他杂项数据,只要它是可用的。
三个步骤的过程,如下所示,将被用来规定最终的成绩给每个学生。我将把这整个过程称为“模型”。
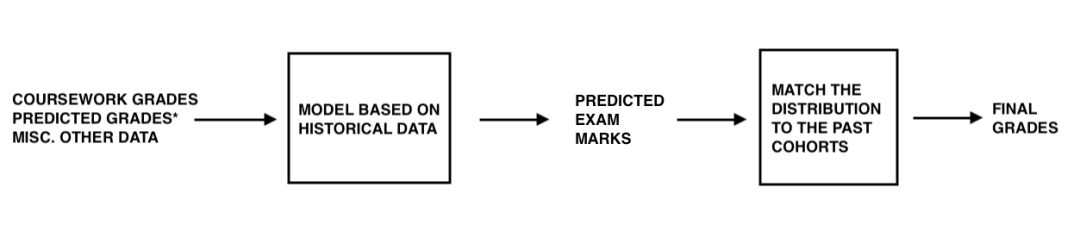
根据历史模式,这个模型可以有很多名称:统计建模、机器学习、数据分析、大数据、人工智能。所有这些术语都指的是使用历史数据来预测未来事件结果的同一套狭义过程。
不幸的是,正如三位著名的研究人员在他们的教科书中所表达的那样,“这个过程是“以证据为基础的”这一事实绝不能确保它将导致准确、可靠或公平的决定”。
在本文中,我将以前面的陈述为基础,让你相信使用统计模型给学生们评定最终分数是一个可怕的想法。
而如果你是这次考试的考生或者家长、老师,请一定要读完文章再拿起你的武器。
IB用统计模型打分有什么问题?
让我们从IB所描述的过程中明显的问题开始。
这里我主要提出七个明显的问题(以及一些较小但同样重要的问题):
1. 双重危险
如果一个学生在课程中表现不好,他们将会因此被打两次低分:一次是输入模型中课堂表现的成绩,另一次是根据计算最终成绩的IB评分规则,重新预估的成绩。这是因为该模型将根据课程作业来预测最终成绩。然后,期末成绩将与课程成绩结合起来得到期末成绩。
2.历史偏见
一项基于美国国家教育统计中心(National Center for Education Statistics)数据的研究得出结论,中学教师对“有色人种学生和背景不利的学生”的预期往往较低。这是有问题的,因为预测分数在模型中扮演着重要的角色。
3.规模越小,错误越大
规模较小的学校(占IB学校总数的15% - 30%)在模型预测上,与规模较大的学校相比,会出现更大、更频繁的错误。这是表征偏差的一个例子。

假设最大的IB学校有300个班级(根据2019年IB数据)。如果你是一所5人班的学校的学生,你的期末成绩将比300人班的学生的平均错误率高出25%左右。上面的图表描述了这种比较误差是如何随着班级规模的增加而衰减的。原则很简单:你拥有的学校数据越多,你的预测就越准确。
4.评估偏差
如果不同学校的评估过程不同,会影响模型对待不同学校学生的方式。为社会经济弱势群体服务的学校,对学生的评价可能不那么频繁。这将导致成绩较差的学生获得的预期成绩,与那些考试频繁的学校里成绩较好的学生相比,预期成绩的准确性较低。此外,较差的学校可能会有更大的班级规模。一个给10个学生分配预测分数的老师会比一个给30个学生分配预测分数的老师做得更好。
5.可获得的附加数据
IB表示,他们将在“可获得的”附加数据中补充课程成绩和预测成绩。这可能是有问题的,因为它可能在预测中引起偏见,并将导致一些学校的预测比其他学校的预测更准确。
6. 偏态分布
成绩非正态分布的学校会有糟糕的预测。如果一所学校的分数分布是左偏的(优等生!)或者是右偏的,那么这个模式对学生的影响就会更差。
7. 分布转移
如果学校的学科老师在去年和今年之间发生了变化,那么他们的预测成绩和最终成绩之间的历史关系将与当前关系不匹配。这可能会导致系统性的更糟糕的预测。
这些都是基于统计学显而易见的一些错误。根据IB决定使用的模型类型,还可能出现许多其他微妙的问题。
我个人认为,这些零星的“开胃菜”论点应该足以结束这个实验。但是别着急,咱们继续阅读接下来这些稍微复杂一点但更令人不安的问题。
在一个统计模型中,学生的未来不应该受随机噪音的支配
在统计领域有一个普遍的说法:“所有的模型都是错误的,有些模型是有用的。”
模型是基于经验的历史模式对现实的一种近似值:所有的预测都是粗略估计,没有一个模型能够完全肯定地预测未来。此外,由于随机噪声的存在,每个模型的预测都存在一定的不确定性。如果IB使用一个模型来给学生分配期末成绩,这个模型将不可避免地出现错误。
让我们假设IB构建了一个“准确率90%”的模型。这是一个几乎不切实际的雄心勃勃的目标,在实践中难以实现。这意味着每10名学生中至少有1人的期末成绩不正确。
换句话说,这相当于中国、德国、印度、新加坡和英国所有IB学生的错误成绩。
但IB对这10%的不准确程度似乎非常满意。因为他们向学生保证,他们将“与去年的成绩分布相匹配”。
这能抵消模型预测中的不准确性吗?绝对不会。这是一个表面上的改进,它还有一个额外的好处,那就是为IB提供了一些合理的推诿能力。虽然IB可以使当前分布看起来像过去的分布,但他们无法保证学生之间的相邻,尽管有与如果考试照常进行时一样的分布。
假设我可以建立一个模型,根据任意的正态分布随机分配给每个学生一些分数。然后,我可以使用这些标记,调整我的成绩等级,以匹配去年的最终成绩分布。这是否弥补了我的“模型”以一种完全脱离现实的方式分配分数的事实?不,没有。前一个例子是病态的,在现实中,一个坏的模型会默默、但严重地伤害某些学生群体。
是的,模型是非常有用的工具,它可以帮助我们大规模地做出决策。其将不可避免地在我们的未来发挥很大的作用。这确实意味着,机构应该能够规避在何种模式适合时的道德考量。因为一个黑箱决策机制认为学生不值得获得这个机会,就剥夺学生辛辛苦苦在伦敦政治经济学院(London School of Economics)获得的一席之地,这是否道德?
告诉一个17岁的孩子,因为他们的错误预测是“做生意的成本”,所以他们不能和同龄人一起毕业,这是否道德?我相信,IB在做业务选择时可能忽略了一些关键的道德考量。
模型是怎么出问题的?
在进入最后一个论点之前,我们需要了解能做出正确预测的模型可能仍然完全不正确。
模型非常强大,但也同样非常愚蠢:追求精确使模型可以做出一些比较好的预测,但这也使它们完全无效。模型具有检测大量数据中的微观模式的超强能力,它会想方设法使其能够有效地预测结果。研究人员无法控制模型将选择检测的模式。因此,模型将尽一切可能使自己更具预测性-即使这意味着要利用虚假的关系来预测结果。
以下面的这些图为例:
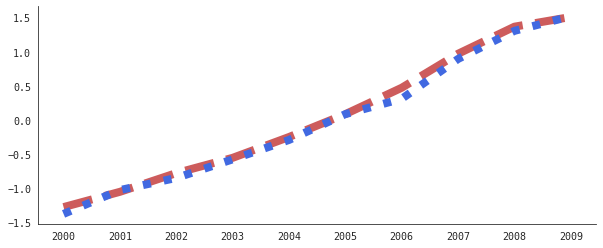
我训练了一个模型,该模型几乎完全适合上面的数据。给定蓝线,它可以很好地预测红线的值(反之亦然)。现在,让我将这些数据重新关联起来。

红色实际虚线代表美国人花在宠物上的钱,蓝色虚线是在加州的律师人数。我们知道,不可能将上述两个数量相关联-这只是一个巧合。
然而,任何模型都将可以基于这两个变量预测一个关系函数。
任何一个有理智的人都不会认为认为2010年花在宠物上的钱突然下降会导致加州律师人数相应下降,但是,如果我根据此数据训练模型,则很容易受到这种错误假设的影响。即使当我尝试通过给模型适当的数量来纠正这种矛盾时,也应该 为了能够预测律师的人数,它选择使用错误的信号(花在宠物身上的钱)来预测结果。
作为研究者,不可能阻止模型学习这些不正确的关系。这一点很重要:仅仅因为模型是可预测的并不意味着它是正确的。准确的模型可能是错误的模型,而虚假的相关性如果没有通过审核,也将非常危险。
我没输入有偏见的数据啊,模型是怎么自己会学歧视的?
即使在模型中隐瞒相关信息,模型也会学习学生的性别、种族和社会经济地位这些因素。因此,IB模型将歧视某些学生群体,产生不公平的结果,这在统计上是不可避免的。
您可能会认为,一个不了解性别/种族/社会经济地位的模型应该无法基于这些属性进行区分啊。这种思路被称为“无知中的公平”。让我们看看专家对此如何说:
有些人希望删除或忽略敏感属性……以某种方式确保公正性……不幸的是,这种做法通常既无效又有害。
回到现实,我将建立一个模型来预测纽约某高中的各项指标。基于它所在地区和几项其他数据,这非常类似于 IB所做的事情(它们正在使用类似的指标)。
我首先利用这个模型来预测这所高中的毕业率是否高于/低于全国平均水平,结果准确率高达80%。请记住,此模型没有被输入任何种族的数据,任何高中学生群体的社会经济地位或性别。

那么,这个模型是如何学习预测毕业率的呢?
回答这个问题之前我将在这里略过一些技术细节,先简单的利用这同一个模型去预测:这是个少数族裔(黑人/西班牙裔)占多数的高中吗?
一个很大胆的猜测是,如果我们的模型可以高精度地检测到少数族裔(黑人/西班牙裔)占多数的高中,那可能它在之前就利用了这个特征,并利用了这一点来预测毕业率。

最终结果很明显,我们的模型可以比预测毕业率更准确地预测高中的多数种族。这意味着我们的模型肯定具有种族意识。我们没想到它会学到关于学生种族的任何信息,但是,该模型决定需要了解此信息才能预测毕业率。我们没有为该模型提供有关学生种族的任何数据,该模型只是继续学习而已。
用同样的方法我们会发现,该模型可以识别出哪些学校的学生处于经济不利地位,精确度达到75%。这意味着我们的模型也具有经济意识。
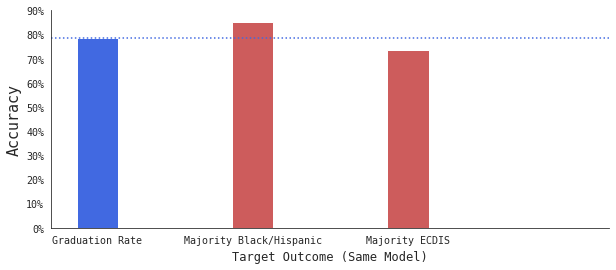
为了确保这不是侥幸,我们检查该模型是否可以检测到女性人口占多数的学校:

该模型的准确度低于50%。这比随机猜测略差。该模型显然在做出决定时并未考虑学校的多数性别。
实际上,让我们假设我们再创建一个替代模型,同时增加关于这个高中多数族裔的数据(除了与原始模型相同的数据点),我们可能会预期该模型的毕业率准确性会随着我们的提高而大大提高。但事实上,备用模型的准确性在增加了“种族”这一指标后,仅增加了约1%。这说明,在我们录入种族数据之前,我们的模型已经某种程度上自行获取了这一信息。
重申:当我们建立基于测验分数和学校位置来预测高中毕业率的模型时,我们没有为模型提供任何有关种族,社会经济地位或性别的信息。我们的模型只是简单地意识到,如果它可以确定学校的种族/经济构成,那么就可以确定毕业率。因此,即使IB没有给出模型敏感数据,模型也会推算出来。
那么,当模型了解学生的性别/社会经济地位/种族,然后错误地使用这些东西来预测他们的最终成绩时,会发生什么?
就像“花在宠物上的钱”实际上并不能告诉我们“加利福尼亚州律师的数量”一样,知道种族、社会经济地位、学生的性别也不会告诉我们有关其最终成绩的任何信息-即使此数据可能对预测有用。
由于我们没有“一种原则性的方式来说明这种关系在什么时候令人担忧以及在什么情况下可以接受 ”,使用模型将导致对学生群体的不公平预测。
机器学习的形成性结果表明,IB在统计上不可能确保任何模型都是完全公平的。这意味着国际文凭组织使用的任何模型都不可避免地会通过以下三种方式来歧视学生:
它可能会基于某些敏感属性对学生进行降分,并为某些群体系统地分配较低的成绩。 例如:模型可以选择基于学生的性别(或种族/社会经济地位)来分配成绩。它可能会系统地为女数学学生分配比男数学学生低的分数。
基于某些敏感属性,对于某些学生可能会有更高的错误预测率。 例如:根据学生的种族(或性别/社会经济地位),模型可能会以不同的比率错误地使学生失败(毁灭性的,但不可避免的!)。它可能以比亚裔学生更高的比率错误地使黑人学生遭遇学术失败。
基于某些敏感属性,某些组的准确性可能较低。 例如:根据学生的社会经济状况(或性别/种族),模型在识别应失败学生方面可能具有不同的精度。在剔除有钱但没有通过考试的学生(用手术刀剔除)方面较精确,而在剔除贫困但没有通过考试的学生上(用黄油刀剔除)方面较不准确。
如上所述,对于每种敏感属性,这三种情况中的两种是不可避免的。这些“歧视性“将在IB选择的任何模型中体现出来。这里有一个不得不做的妥协:研究人员将不得不决定要牺牲的两个标准中的哪一个。
因此我们必须谨慎思考这个问题:使用一种系统地对某些学生的表现持悲观态度的不公平模型是否合乎道德?如果模型利用敏感属性来分配等级,使用模型是否公平?
那么我们现在该怎么办?
我已经花了很多时间讨论这个统计问题了。
但我们无法得出一个完美的答案:只有一堆错误的答案。这是一个外包的黑匣子模型,其历史数据有限,没有对决策机制进行监督,并且只有三个月的研究和生产时间,这使情况进一步复杂化。
当然,数据分析和机器学习是功能非常强大的工具,但是需要在适当的情况下使用它们,并且要格外小心。当您可以显着改变人口中弱势群体的生活结局时,您需要在决策中采用更高的细微差别。这种情况引发了一种过程解决方案,而不是智能的“建模”解决方案。
不幸的是,我对教育领域了解不足,无法提出一个好的选择。但是,我对自己的数学能力充满信心,可以确定当前的解决方案无疑是错误的。最好有一个延迟且次优的解决方案,而不是具有歧视性和错误的解决方案。我意识到这样一个事实,即这可能会使文章显得有些偏执,但我的目标是仅仅在非常敏感的情况下提高对潜在问题的认识。
作为学生/家长/老师:第一步是不屈服于结果偏见。可以很容易地说“让我看看模型的结果,然后再决定是否接受它”。如果您认为结果合法化后受到了不公正的对待,那么您将无能为力。与您的管理员和IB社区中的其他人共享本文。要求一个更好,更公平,更透明的流程(support@ibo.org)。向您希望报名的大学提出您的问题,并向他们询问更公平的替代录取流程(info@officeforstudents.org.uk等)。
最后,我想提醒所有政府和大学,在宣布接受这个坏主意之前谨慎思考。最应该被关注的是,如何从跨学科的角度来看待这个陈规定型的商业决策,认真考虑潜在的后果。关于机器学习公平性的讨论显然未能吸引到参与此操作的许多利益相关者,或许学术界应该更关心这些问题。
相关报道:
http://positivelysemidefinite.com/2020/06/160k-students.html



